Stylization
TextBoost also offers high-quality personalization of style!

In this paper, we introduce TextBoost, an efficient one-shot personalization approach for text-to-image diffusion models. Traditional personalization methods typically involve fine-tuning extensive portions of the model, leading to substantial storage requirements and slow convergence. In contrast, we propose selectively fine-tuning only the text encoder, significantly improving computational and storage efficiency. To preserve the original semantic integrity, we develop a novel causality-preserving adaptation mechanism. Additionally, lightweight adapters are employed to locally refine text embeddings immediately before their interaction with cross-attention layers, greatly enhancing the expressiveness of text embeddings with minimal computational overhead. Empirical evaluations across diverse concepts demonstrate that TextBoost achieves faster convergence and substantially reduces storage demands by minimizing the number of trainable parameters. Furthermore, TextBoost maintains comparable subject fidelity, superior text fidelity, and greater generation diversity compared to existing methods. We show that our proposed method offers an efficient, scalable, and practically applicable solution for high-quality text-to-image personalization, particularly beneficial in resource-constrained environments.
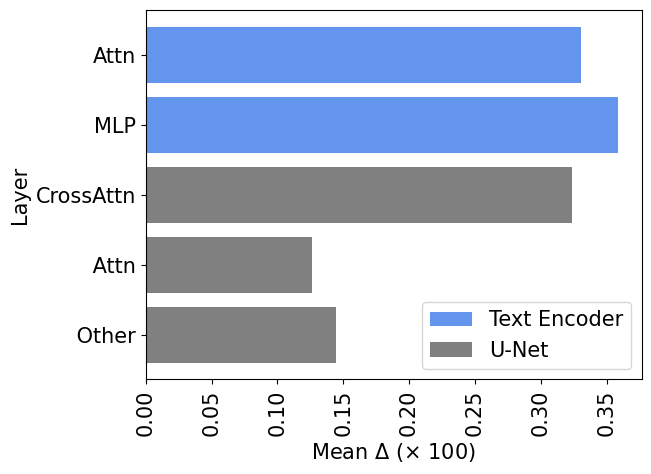
Unlike previous methods that predominantly fine-tune the U-Net or the concept token itself, we systematically re-evaluated which parts of the text-to-image diffusion model are most critical for effective personalization. By quantifying parameter changes across layers during full model fine-tuning, we discovered that the text encoder parameters exhibit significantly larger adjustments than the U-Net parameters. This pivotal finding highlights the previously overlooked importance of the text encoder, motivating our approach to exclusively fine-tune the text encoder for efficient and scalable personalization.
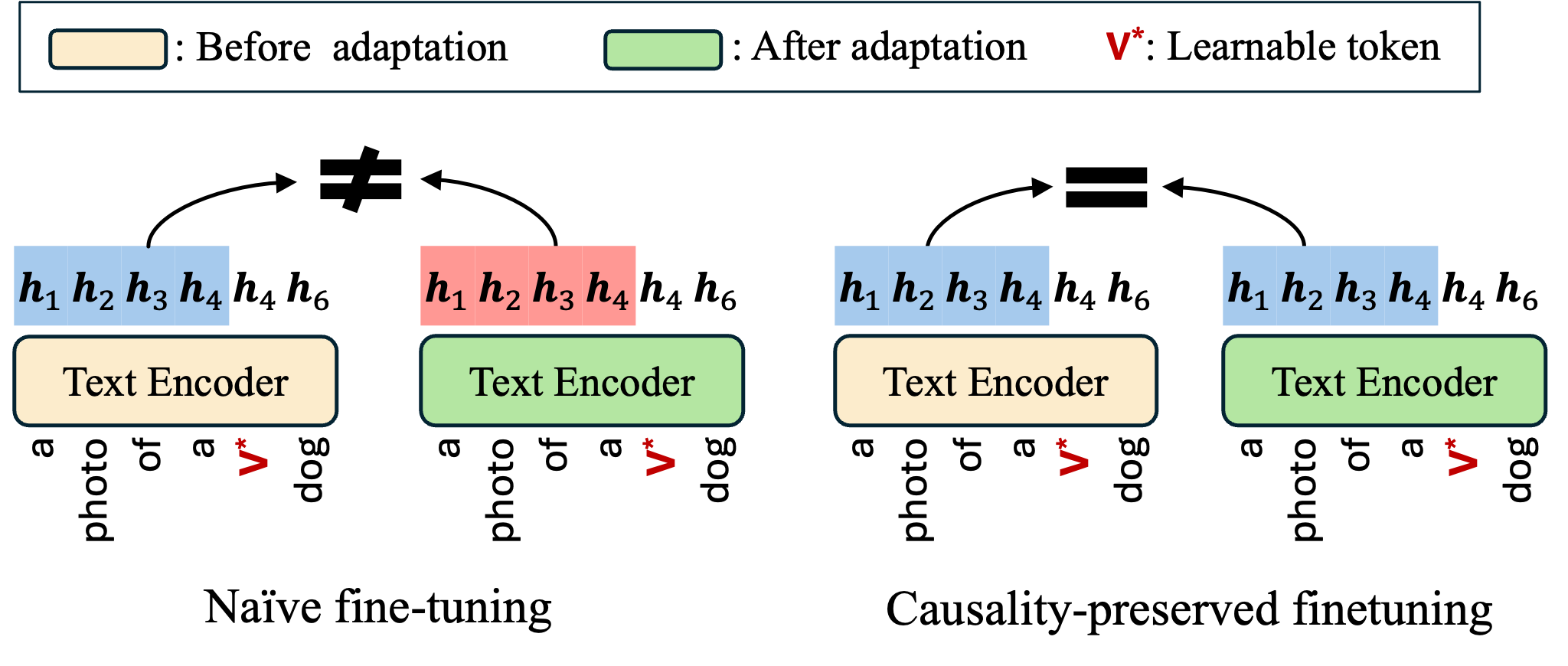
TextBoost Overview
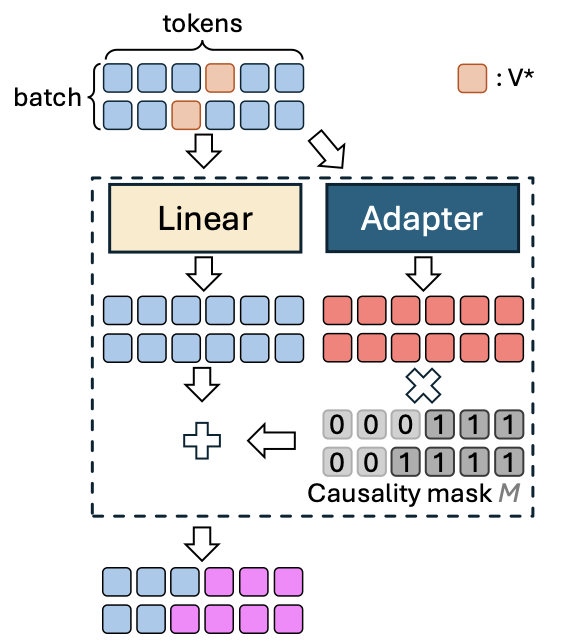
Causality-Preserved Adaptation
Unlike traditional personalization methods that update the U-Net, TextBoost selectively fine-tunes only the text encoder for efficient one-shot text-to-image personalization. Additionally, lightweight adapters are employed to locally refine text embeddings immediately before their interaction with cross-attention layers, greatly enhancing their expressiveness with minimal computational overhead.
To preserve the original semantic integrity of the pretrained text encoder, we introduce a novel Causality-Preserved Adaptation (CPA) mechanism. This technique ensures that the embeddings of tokens preceding the learned concept token (V*) remain completely unchanged. By preserving the auto-regressive causality up to V*, CPA prevents catastrophic forgetting and preserves the model's original generative capabilities.
With the same text prompt, TextBoost generates a variety of images featuring the subject.

TextBoost also offers high-quality personalization of style!
@article{park2026textboost,
title = {Boosting Text Encoder for Personalized Text-to-Image Generation},
author = {Park, NaHyeon and Kim, Kunhee and Shim, Hyunjung},
journal = {Transactions on Machine Learning Research},
year = {2026},
}